Laboratory products
Published over 5 years ago. See the latest and most current information on Laboratory products.
Effective translational research requires effective and robust multi-omics data integration, in order to ensure complete and correct description of the mechanisms of complex disease such as cancer. This is very much about ‘the sample’ as we have to analyse it using different workflows and sampling methodologies. For example, a next gen sequencing workflow that obtains sequence data is very different to an LC/MS metabolomics workflow obtaining metabolite data.
It isn’t only translational research that benefits from such ‘multi-omics’ workflows but the aptly named rapidly evolving field of ‘sytems toxicology’.
We are now well into the 21st Century and have already seen many truly pivotal advances in the life sciences. Our understanding of disease, at the molecular level, has benefitted exponentially. Rather as we once mapped the world’s oceans, we continue to construct ever more detailed ‘maps’ of disease. As these maps become more detailed, we see ‘pathways’ that describe the mechanism of specific diseases, be it neurodegenerative, cancer, cardiovascular or other. As a consequence, we have developed complex methods for culturing cells and reconstructed tissues, through measurements of cellular changes at a molecular level (so-called ‘omics technologies) to vastly improved computing capacity that can be applied to make sense of the huge volumes of data generated from multiple omics approaches (e.g., genomics, transcriptomics, proteomics, and metabolomics), as is the motivation of the human microbiome project.
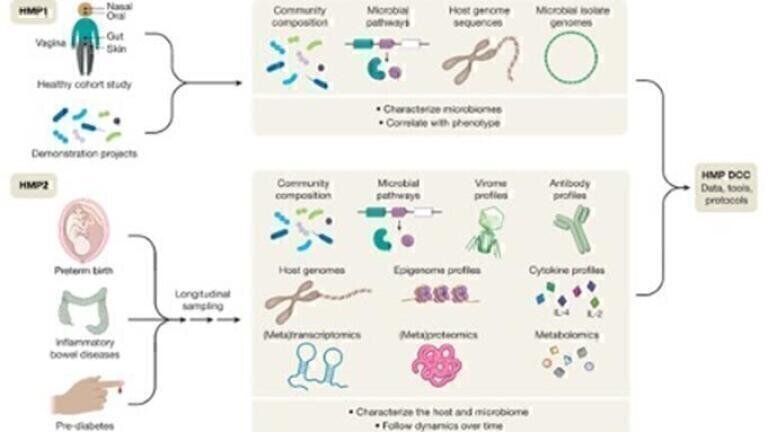
Figure 1. Multi-omics data integration for the human microbiome project
High-quality multi-omics studies require:
- proper experimental design
- thoughtful selection, preparation, and storage of appropriate biological samples
- careful collection of quantitative multi-omics data and associated meta-data
- better tools for integration and interpretation of the data,
- agreed minimum standards for multi-omics methods and meta-data,
Ideally such a study should involve multi-omics data being generated from the same sample(s) though this can be more challenging due to limitations in sample access, biomass, and cost. A good example of this is the fact that formalin-fixed paraffin-embedded (FFPE) tissues are compatible with genomic studies but not with transcriptomic or, until recently, proteomic studies, due to the fact that formalin does not stop RNA degradation and paraffin can interfere with MS performance thus affecting both proteomic and metabolomic assays.
There is a case to be made for basing multi-omics experimental design requirements on that used for metabolomics. Metabolomics experiments are highly compatible with a wide range of biological samples including blood, serum, plasma, cells, cell culture and tissues; which also happen to be preferred for transcriptomic, genomic and proteomic studies; assuming a consistent sample storage protocol.
Metabolomics experiments require fast sample processing times, demanding the same of transcriptomic and proteomic studies, in order to ensure consistency. Moreover, metabolites are also particularly sensitive to environmental influences (diurnal cycles, heat, humidity, diet, age, developmental stage and social interactions) and the tracking of sample meta-data is very important to mitigate the effects of environmental confounders, and to facilitate transparency and reproducibility.
As stated at the start, it is ‘all about the sample’ and the integration of omics data strongly depends on rigorous and consistent sample prep, and sample variation over pretty short periods of time. This demands accurate tracking of each step of the sample prep conducted in the different omics workflows, including the multitude of basic, yet critical liquid handling steps, involving anything from serial dilutions to plate normalisation.
Robust, repeatable sample prep, requires rigorous adherence to protocol in order to obviate the risk of contamination, ease of method transfer, and most important, the ability to digitally capture a complete and accurate record of every single step of the sample preparation, including labware used, pipette calibration data, reagent prep temperatures, tube or microplate agitation speeds, and much more, in order to facilitate the translation of omics data sets upon completion of each analytical workflow.
High-quality multi-omics studies require:
• proper experimental design
• thoughtful selection, preparation, and storage of appropriate biological samples
• careful collection of quantitative multi-omics data and associated meta-data
• better tools for integration and interpretation of the data,
• agreed minimum standards for multi-omics methods and meta-data,
Ideally such a study should involve multi-omics data being generated from the same sample(s) though this can be more challenging due to limitations in sample access, biomass, and cost. A good example of this is the fact that formalin-fixed paraffin-embedded (FFPE) tissues are compatible with genomic studies but not with transcriptomic or, until recently, proteomic studies, due to the fact that formalin does not stop RNA degradation and paraffin can interfere with MS performance thus affecting both proteomic and metabolomic assays.
The current Covid-19 pandemixc presenets a very pertinent and ‘current’ example of the importance of multi-omics and pathway-based approache sin pursuit of a better understanding of its mechanism and identification of ways in which its effects can be mitigated. To date, much effort has been expended in better understanding the pathogenicity of SARS-CoV-2. A unique aspect of the disease has been its ability to act all over the body rather than being limited to the respiratory tract, including causing strokes in otherwise healthy, younger patients. Especially dangerous is the occurrence of a ‘cytokine storm’ in some patients, 7 to 10 days following the onset of infection.
The data gathered, thus far, by the international scientific community, detail the genomes and mutations of SARS-CoV-2 variants across different locations; the structure of the viral proteins; their host targets in human cells; the transcriptomics changes in infected cells; cell or tissue-level differences in the blood or in the body of COVID-19 patients; and human genomic information from patients. It has been suggested that the only way to understand this data is by taking a ‘systems approach’ that goes beyond individual actions, to connections, causes and consequences.
Ultimately, it is ‘all about the sample’ and the integration of omics data strongly depends on rigorous and consistent sample preparation protocols, in order to reduce sample variation over short periods of time. This demands accurate tracking of each step of the sample prep conducted in the different omics workflows, including the multitude of basic, yet critical liquid handling steps, involving anything from serial dilutions to plate normalisation.
Inevitably, such work is conducted in disparate locations, especially with most countries under lockdown, and with the benefits of remote operation coupled with ease of protocol sharing and method transfer can only heighten the probability of success for such vital systems-level investigations.
Andrew Alliance’s cloud-native OneLab ecosystem ensures rapid, intuitive and precise protocol creation, with ease of method transfer to other labs, minimising intra- or inter-lab variability. As a consequence of it being ‘cloud-native’, it also means that these protocols can be executed, and monitored, remotely. This is especially important during periods of lockdown where the majority of research staff are required to work remotely, often from a home office.
This same scenario also demands both flexibility for assay development, often requiring the ability to switch in/out different ontologies, coupled with full traceability.
Lab 4.0 and the concept of the ‘connected lab’ very much comes into its own here.
Wireless execution of these protocols on its increasing range of connected devices, enabling fully automated liquid handling (Andrew+), guided pipetting (Pipette+), shaking (Shaker+)m rapid heating/cooling (Peltier+), magnetic bead separation (Magnet+), or micro-elution for SPE (Vacuum+) defines not only the blueprint for the connected lab of the future but also the capability necessary to realise the demanding sample prep requirements of multi-omics data integration, and therefore, pathway-based translational research.
Figure 2. Andrew+ offers fully automated pipetting, as well as more complex manipulations, using a wide range of Domino Accessories and Andrew Alliance electronic pipettes. It executes OneLab protocols, enabling rapid transition from laborious manual procedures to error-free, robotic workflows.
If we now divert our gaze across to those critical teams involved in identifying off pathway effects and toxiological endpiints for both pre-clinical and clinical trials, we run into the area of ‘systems toxicology’, essentially the application of pathway-based approaches to a filed that ahs chnaged little in over a century.
“Not responding is a response - we are equally responsible for what we don’t do.” (Jonathan Safran Foer, 2011).
Life-saving therapeutics and vaccines undergo a sophisticated array of both in-vitro, and later in the drug development process, in-vivo testing. Different animal models are used, with the aid of establishing drug safety, as well as parameters of use in human beings.
DMPK, or Drug Metabolism and Pharmacokinetics, is an important part of studies often referred to as ADME (Absorption, Distribution, Metabolism, and Elimination):
• Absorption (how much and how fast, often referred to as the absorbed fraction or bioavailability)
• Distribution (where the drug is distributed, how fast and how extensive)
• Metabolism (how fast, what mechanism/route, what metabolite is formed, and whether they are
• active or toxic)
• Elimination (how fast, which route).
In the drug discovery process, early in vitro ADME screening and in vivo PK profiling provide a basis for choosing new molecular entities (NMEs) and lead compounds that have desirable drug metabolism, PK or safety profiles, necessary for drug candidate selection (CS) and late stage preclinical and clinical development. The ADME properties of a drug allow the drug developer to understand the safety and efficacy data required for regulatory approval.
Toxicology tests are often a part of this process, yielding the acronym ADMET.
Today, such studies are performed both in vitro and in vivo, and have led to more standardised procedures across the pharmaceutical industry.
There has been understandable concern over the ways in which animals have been used and treated as part of this process. As such, the principles of the 3Rs (Replacement, Reduction and Refinement) were developed over 50 years ago providing a framework for performing more humane animal research. Since then they have been embedded in national and international legislation and regulations on the use of animals in scientific procedures, as well as in the policies of organisations that fund or conduct animal research. Opinion polls of public attitudes consistently show that support for animal research is conditional on the 3Rs being put into practice.
Replacement refers to technologies or approaches which directly replace or avoid the use of animals in experiments where they would otherwise have been used, for example the use of methods employing human embryonic stem cells as alternative ways of conducting ADMET studies. Refinement refers to methods that minimise the pain, suffering, distress or lasting harm that may be experienced by research animals, and which improve their welfare. Refinement applies to all aspects of animal use, from their housing and husbandry to the scientific procedures performed on them.
By contrast, reduction refers to methods that minimise the number of animals used per experiment or study consistent with the scientific aims. It is essential for reduction that studies with animals are appropriately designed and analysed to ensure robust and reproducible findings.
Reduction also includes methods which allow the information gathered per animal in an experiment to be maximised in order to reduce the use of additional animals. Examples of this include the micro-sampling of blood, where small volumes enable repeat sampling in the same animal. In these scenarios, it is important to ensure that reducing the number of animals used is balanced against any additional suffering that might be caused by their repeated use. Sharing data and resources (e.g. animals, tissues and equipment) between research groups and organisations can also contribute to reduction.
Regarding ‘reduction’ much emphasis is placed on the importance of minimising the number of animals used in a study. Over the past several years, it’s become increasingly apparent that many lab studies, especially in the life sciences, are not reproducible. As a result, many putative drug targets or diagnostic biomarkers can’t be validated. Some estimates suggest that more than 50% of all published life sciences research is irreproducible, and some indicate that the figure might be even higher. The problem flew below the radar for years. A 2012 comment in Nature by C. Glenn Begley, a former vice president at Amgen, and Lee M. Ellis, an oncologist at the University of Texas M. D. Anderson Cancer Center, drew attention to the problem. They described Amgen scientists’ attempts to replicate the key findings in 53 ‘landmark’ fundamental cancer studies that claimed to identify potential new drug targets. They were able to replicate the findings in only 11% of the cases.
This ‘concern’ has not dissipated but has triggered a number of subsequent studies aimed at identifying the reasons for such has high levels of irreproducibility. There a number of causes, which vary from the deliberate falsification of research, with increased pressure being brought to bear on the peer review process, to the tools we use in the laboratory and the ways in which those can contribute to erroneous data. These include, but are not limited to, the means by which powders (e.g. precision weighing scale) and liquids (e.g. pipettes) are handled, mixed and transferred; as well as the way in which one research group might interpret and repeat the work of another. This latter point might seem odd when considered alongside tools but bear in mind that the way in which the tools are used depends upon an accurate description and interpretation of the protocol used, an important area of research and development in its own right.
In order to respect the 3Rs, researchers must constantly strive to ensure that the latest techniques tools are fully used, taking full advantage of lab automation in order to minimise unnecessary replication and use of animal models.
ILM Guide 2026/27
















.jpg)



